Watch Out for UUIDs in Request Parameters

The Plugin:https://github.com/GeoffWalton/UUID-Watcher
Some time ago on the TrustedSec Security Podcast, I shared a Burp Suite plugin I developed to hunt Insecure Direct Object Reference (IDOR) issues where applications might be using UUIDs or GUIDs (unique identifiers) as keys, assuming discovery attacks will not be possible. The plugin produces a report that helps identify which resources should be reviewed for potential problems. I have added several improvements including some rudimentary understanding of GraphQL endpoints, filename selection, and the ability to ignore cookies. I also rearchitected it considerably. It no longer acts as a scan check, which makes it more efficient to re-run or use against historical data. It also means you can more easily target only parts of the site map, making it easy to ignore parts of an application such as /admin.
Background
If you’re the type of person that tests web applications all day every day and immediately understand why correlating unique identifiers in HTTP requests with any of the HTTP responses in which they appear is of interest, skip to the following section. However, I want to provide some background for those not testing applications regularly.
Using a very large, sparsely populated keyspace as an access control mechanism is a design pattern that has become common in web APIs of all kinds including SOAP, REST, and GraphQL. This is often seen where records are strictly related. For example, a work order might be related to an invoice, or there is a single data owner…my profile belongs to me alone. It can be used anywhere where untrusted clients don’t need to be able to enumerate resources. There are other considerations like temporal components to authorization to consider, but these are out of scope for this discussion.
This design pattern has considerable advantages. Some significant ones are that the application does not need to implement a complex permissions model. Record level access control logic is notoriously difficult to design without error and apply uniformly and is usually expensive in terms of resource utilization due to more round trips to databases or to other authorization and identity servers. Another key advantage is the reduction of coupling. An example here would be hosting media items in an Amazon S3 bucket and naming them with unique identifiers. In that example, S3 does not have and does not need any understanding of the application’s security model. It’s no surprise many applications are architected around this concept.
Things can and do go wrong, however. The specific issue my plugin helps look at is identifiers becoming a kind of secret. To better understand how this might look and how it becomes a vulnerability in practice, consider the API endpoints below. (We will assume that each endpoint needs a bearer token in the Authorization header except POST /user/signIn, and that this is a subset of calls in a large complex application.)
| POST /user/signIn Request body: {“username”:”[email protected]”,”password”:”LetMeInPlease!”} Response body: {“error”:”success”, “token”:”26B03262-2423-465D-999B-560B74476307”, “userid”:” 98A4FE69-8F21-4095-8CED-0C683F1BAB31”} |
| GET /user/{userid} Request Path (userID): 98A4FE69-8F21-4095-8CED-0C683F1BAB31 Response body: {“error”:”success”,“firstName”:”Test”,”lastName”:”McTesterman”,”OrgId”:”0B2C84EB-9151-4B51-B0B6-145567E9CA02”,…} |
| GET /tradeSecrets/schematic/byOrgId/{orgId}/{page} Request Path (orgId): 0B2C84EB-9151-4B51-B0B6-145567E9CA02 (page): 1..N Response body: {“error”:”moreRecords”,”schematicIds”:[“1565352A-281A-4DB6-A536-5D4D594691B2”,…]} |
| GET /tradeSecrets/schematic/{schematicId}/ Request Path (schematicId): 1565352A-281A-4DB6-A536-5D4D594691B2 Response Content-type: image/tif Response body: BLOB |
So far so good. We can’t get schematics that don’t belong to our organization because we need the orgId that is only provided in our user information obtained from /user/{userId} before we can gain a list of schematicId values, all using impossible to brute-force identifiers.
Now, ACME has requested the application developers provide a way to share schematics between organizations because they want to collaborate on putting a Wile-E-Enterprises warhead on one of its Road Runner seeking missiles, so to speak. Users will need the ability to search for other organizations to share things with, and there will need to be a way to tell the back-end which organizations to share items across. To keep the API flexible and useful, developers might expose some things like this.
| GET /organization/byName/{name} Request Path (name): “American Company Making Everything” Response body: {“error”:”success”, “results”:[ {“DisplayName”:”ACME”,”orgId”:”77126E08-36D9-4BC2-B96C-93637B6D17CA”…},{…]} |
| POST /tradeSecrets/schematic/{schematicId}/share Request Path (schematicId): 1565352A-281A-4DB6-A536-5D4D594691B2 Request Body: {“orgId”:”77126E08-36D9-4BC2-B96C-93637B6D17CA”} Response body: {“error”:”success”} |
The intention is that someone at Wile-E-Enterprises will lookup an organization searching by name and find ACME and whatever other organizations match their query. They will select ACME, and the client web application will POST ACME’s orgId to /tradeSecrets/schematic/{schematicId}/share. Finally, /tradeSecrets/schematic/byOrgId/ will return the given item for both ACME and Wile-E-Enterprises orgId or similar.
The trouble here is that anyone who can sign in can use the /organization/byName functionality, which discloses orgId values for any organization. The developer that implemented the changes either forgot or did not understand that orgId is effectively the secret that provides access to schematic items. Unless someone is stepping through requests with an intercept proxy, this is unlikely to be observed in functional or UAT testing because everything appears to work. It is also the kind of thing security testers might not spot or might mistakenly dismiss.
The Problem
Tools like Auth Analyzer (a fabulous tool by Simon Reinhart) will certainly detect that a resource can be accessed using differently authorized identities. All that really tells us though is that the resource does not do full authorization checking. So, as testers, we must determine if an authorization requirement exists.
Our client is certain to push back and inform us that attackers have no way to discover the unique identifiers. There may be other arguments to make such as irrevocability. That is, once the identifier is known to me—even if you take me out of the group/role/etc.—that is allowed access, unless you lock me out of the app entirely, I can still hit that resource using the previously disclosed id. However, the most significant question is, can someone who should never have had access be able to find that resource?
To answer that question, we will have search all the other HTTP history to see if that identifier shows up in any other responses besides whatever resource provided it to us in the current workflow. Care must also be taken to ensure we used all the lookup resources present in the application in ways that would expose possible leaks; for example, if testing a multi-tenant application, it would be a good idea to search for records known from one tenant while logged in to another.
How My UUID Plugin Can Help
Searching all the request history for all the unique identifiers to make sure there are no possible leaks can big a big task. It might be necessary to look for different encodings. For example, URL encoding might be applied when an identifier is used in a query string encoding ‘–‘as ‘%2d’ but not when the identifier is returned in a JSON body. I have tried to take care of some of these different representations. A single URL string in Burp’s display might represent many logical resources (e.g., /someApp/graphql), so I have tried to extract the operation.
How to Install and Use the Plugin
- Download the current UUID-Watcher plugin.
- Ensure you have JRuby configured in the Extender -> Options tab.
(I recommend using one of the jruby-complete-9.* packages.) - Add the plugin on the Extender -> Extensions tab.
- Load up a Burp Suite Project and Browser and exercise your target application. Be sure to hit any functionality that lists items in collections, search for things, etc.
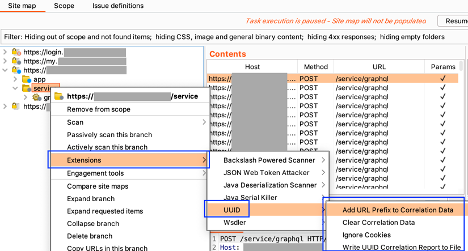
- Locate a portion of the site map you want to generate correlation data over to. Right click and select Extensions-> UUID -> Add URL Prefix to Correlation Data and wait for notification that the data has been ingested.
- Right click anywhere on the site map and select Extensions-> UUID -> Write UUID Correlation Report to File. Select a place to save the file.
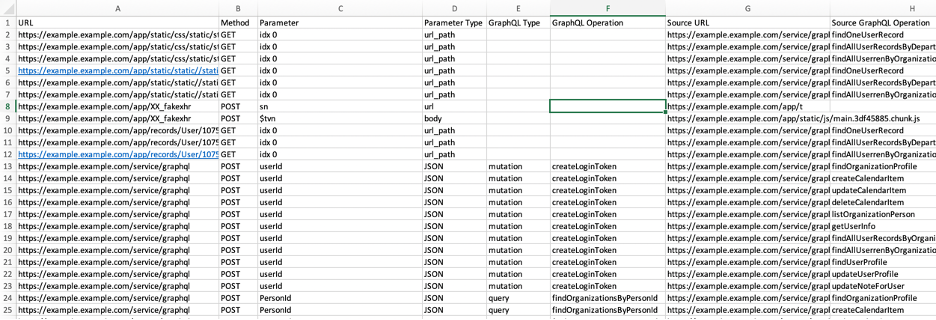
You may discover that there is a lot of noise if the application has a unique identifier in a cookie parameter. If that is the case, you can disable cookies from the plugins menu and regenerate the report. It is not necessary to rescan. With a little luck and some sorting in your favorite spreadsheet program, you will be able to spot some surprising relationships you can then investigate.