
Regular expressions (regex) are used in a variety of ways across technical industries. Developers use it to validate user inputs, and security operations use it to write detections for new attacks and SIEM rules. One of the most common ways I use regex is to search through large amounts of data or clean up output from tools for readability.
The goal of this writeup is to provide a high-level guide for the basic formatting of regex.
There are various forms of regex based on the tool or programming language being used, and each of these implementations may have their own nuanced way of handling specific features. We will not be focusing on those situations. Rather, we will focus on some general commonalities to become familiar with the layout and understanding of how the patterns are laid out. With that understanding, let's jump in to an overview of some of the patterns that are commonly used in regex.
Character Classes
This is a list of characters that may appear in the pattern. While there are a couple “standard” ranges listed below, it is also possible to create a custom character class for when a pattern may only use a small set of specific characters. Character classes are defined by square brackets around the list of characters:
- [a-z] - All lowercase letters
- [A-Z] - All uppercase letters
- [0-9] - All digits
- [aeiou] - Custom list of individual characters to match against
- [^0-9] - Negative match—any character that is not in the list
Occurrences
Often, a pattern will repeat, such as in the example of an IP address. These operators are used to identify how many times the pattern should repeat:
- {1,3} - Define a range—the first digit is the minimum value, and the second is the maximum value
- {4} - Number of times the pattern should be matched
- + - Match one (1) or more of the specified pattern
- * - Match zero (0) or more of the specified pattern
- ? – Match (0)zero or one (1) of the specified pattern
Escape Characters
An element of the regex patterns that can get confusing is the use of escape characters. In each section, there are characters being used in very specific ways, such as square brackets to define a list. There are times when these special characters will appear within your pattern. In order to match these characters within a pattern, a backslash (\) should be added as a prefix:
- [0-9\+] - Pattern could contain 0-9 or a literal +
Meta Characters
Meta characters have special meaning within regex. As such, many of them start with an escape character. In many of these cases, it is a shorthand way of implementing a character class to make patterns a bit more concise:
- . (dot) - Matches any character except newline
- \d - Matches any digit
- \D - Matches any non-digit character
- \s - Matches any whitespace character
- There are multiple whitespace characters [\n\r\t\f]
- \S - Matches any non-whitespace character
- ^ - Start of the line
- $ - End of the line
Putting it Together
Regex can be used to search through large amounts of information, such as grep on the command line. In the first example, I want to use grep to filter my command output to only give me the IP addresses contained within a document. To do this, we first have to understand the pattern of how an IP address looks:
- There are four (4) sets of numbers, called octets, that can range from 0-255.
- Each octet is separated by a period.
There are many different ways this can be represented in regex. Below is just one (1) possible way to represent this pattern:
[1-2]?[0-9]{1,2}\.[1-2]?[0-9]{1,2}\.[1-2]?[0-9]{1,2}\.[1-2]?[0-9]{1,2} |
[1-2]?-The first integer in the octet will be a 1, 2, or may not be three (3) digits[0-9]{1,2}- Look for a digit from 0-9; there may be one (1) or two (2) digits\.- The period between octets
Note that an escape character was used for the period. Otherwise, it would be interpreted as the metacharacter and potentially provide bad results. The search for digits is repeated three (3) more times, for each of the remaining octets. In Figure 1, you will see a command to read a file from the Linux command line. The output from that command will be passed to grep to filter the output down to only the information that matches the regex.

Looking at the output from the command, there is more information than expected. This is the perfect opportunity to emphasize how specific a regex should be. In this case, the pattern also matches a version number within the output. By making the regex more specific to an IPv4 address, it is possible to eliminate the excess information. However, getting too specific with a pattern may also filter out more information than intended and some results may be missed.
Negative matches are used to look for values that do not match a given pattern. In the screen capture below, I have a JSON file with a list of dinosaurs and attributes. With the file in a JSON format, there are several special characters and unwanted whitespace. Using regex search and replace within Visual Studio Code can help clean up this information.
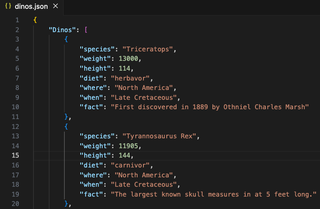
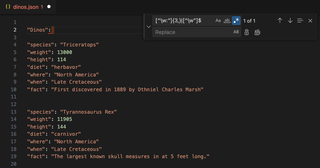
[^\w:",]{3,}|[^\w"]$ |
[^\w:"]- This is looking for any non-word character and excludes colons and double quotes from the search since they appear as part of the key value pair{3,}- Match only if those characters appear three (3) or more times; This is included because some of the values we want to keep include spaces and commas|- Match the pattern before or after this character[^\w"]$- Match any non-word character, except double quotes, at the end of a line
After performing the find and replace in Visual Studio Code, much of the JSON formatting has been removed. This appears to be a good enough solution for this use case.
Lastly, Regex101 is a great resource for testing regex against sample information. This resource also allows users to choose which type of regex, or programming language, they are working with to handle some of the language specific tokens.
Another great tool for helping to reinforce knowledge of the regex classes is https://regexcrossword.com/. The site uses regex in a crossword puzzle for users to solve what the output should be.