Recovering Randomly Generated Passwords
TL;DR - Use the following hashcat mask files when attempting to crack randomly generated passwords.
| 8 Character Passwords | masks_8.hcmask |
| 9 Character Passwords | masks_9.hcmask |
| 10 Character Passwords | masks_10.hcmask |
When testing a client's security posture, TrustedSec will sometimes conduct a password audit. This involves attempting to recover the plaintext password by extracting and cracking the NTLM hashes of accounts in a Windows domain. On average, TrustedSec is able to recover between 50-70% of these passwords because most users continue to choose 'bad' passwords, such as Winter2021!, December21!, etc.

As password managers like Thycotic Secret Server, LastPass, and HashiCorp Vault grow in popularity, the use of randomly generated passwords has increased. This poses a challenge for password recovery, as up until now, the only feasible way to address this issue was to perform resource intensive brute-force attacks. These attacks typically mean trying every single character in every single position of the password (a-z, A-Z, 0-9) and all the symbols on the keyboard. (We’re sticking to English characters here.) The result is 95 characters per position, and with an 8-character password, that means 95^8 possible combinations to test (6,634,204,312,890,625 to be exact). 630,249,409,724,609,375 for 9-character passwords and 59,873,693,923,837,890,625 for 10-character passwords. Even though TrustedSec has some powerful password crackers that can cover the entire 95^8 key space in less than a day, as soon as we bump it up to 9 or 10-character passwords, recovery becomes unfeasible. But…do we NEED to test every combination?

Hypothesis
Let’s presume you’ve encountered a set of hashes you knew were used in a Windows Domain environment and were randomly generated to be 8 characters in length. Immediately, we know that to adhere to password complexity requirements, the password must include 3 of the 4 character classes—uppercase letters, lowercase letters, numbers, and/or symbols.
This means, when considering our key space from above, that we don’t need to test for passwords of all the same characters such as aaaaaaaa or 11111111. Furthermore, because of complexity requirements, you don’t need to test for passwords that are exclusively 2-character classes like aaaa1111.
Taking this a step further, in casually observing randomly generated passwords, I noticed that I rarely see ones using a high quantity of a particular character class. To put it another way, I don’t think I’ve ever seen something like acbdef1! that has six consecutive lowercase letters. If this is true, could we improve our password cracking efforts by removing test cases that rarely or never happen?

Experimentation
To start, I used LastPass-cli to generate my data sets. I should note that I only used LastPass for my tests because it’s what I had available to me. It is, by no means a bad product, and this blog post is not intended to highlight any security weakness with it. I generated three files containing 1 million passwords, each of 8, 9, and 10 characters in length. The commands to do this are as follows:
export LPASS_AGENT_TIMEOUT=0
for i in $(seq 1 1000000);do lpass generate --sync no _tmp 8 >> ~/1M_8.txt;done
for i in $(seq 1 1000000);do lpass generate --sync no _tmp 9 >> ~/1M_9.txt;done
for i in $(seq 1 1000000);do lpass generate --sync no _tmp 10 >> ~/1M_10.txt;done
Next, using a quick Python script, I enumerated all the character classes I found in each file and put them into a spreadsheet, and graphed them out.
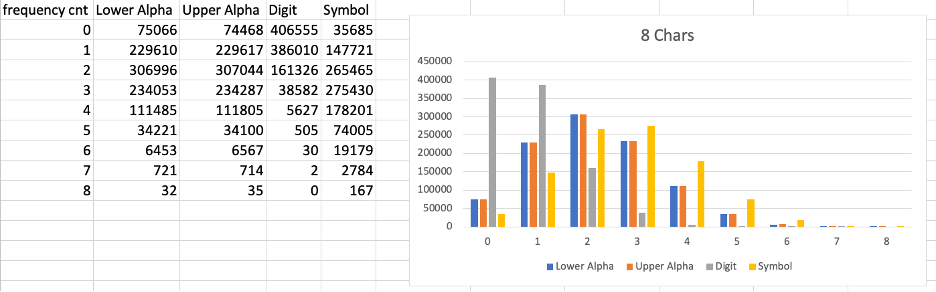
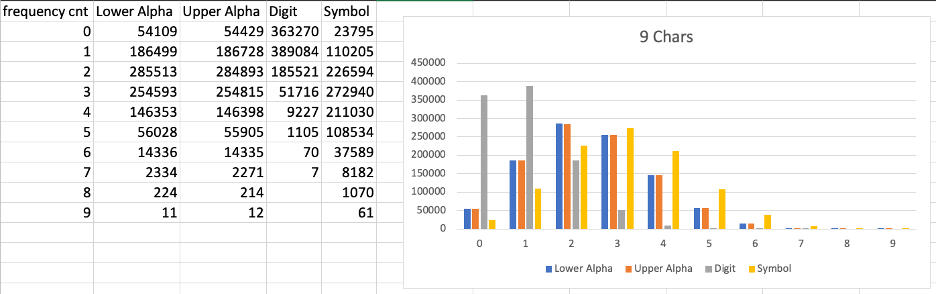
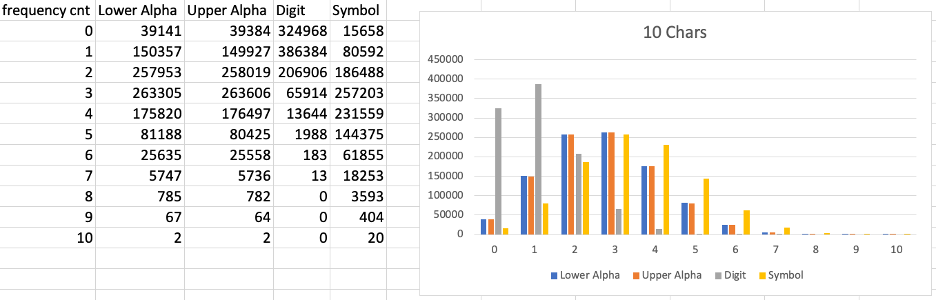
In reviewing these spreadsheets, there are a few things that immediately stood out. First, regardless of the length of the randomly generated password, the vast majority had one to two digits. Additionally, regardless of the overall length of the generated passwords, none contained eight or more digits.
In showing these results to my coworkers, a wise Logan Sampson asked a good question: 'Are these results at all affected by the weight of some character class(es) over others?' That is to say, of the 95 possible characters our random password generator could pick from, only 10 are digits. Therefore, it would make sense that digits are less common in randomly generated passwords.
| Of the Following Key Space: 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ «space»!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ | |
| 10.53% | Are digits |
| 27.37% | Are lowercase letters |
| 27.37% | Are uppercase letters |
| 34.74% | Are symbols |
To test this theory, I went back and tallied how frequently each individual character appeared in all the passwords. Here are the results:
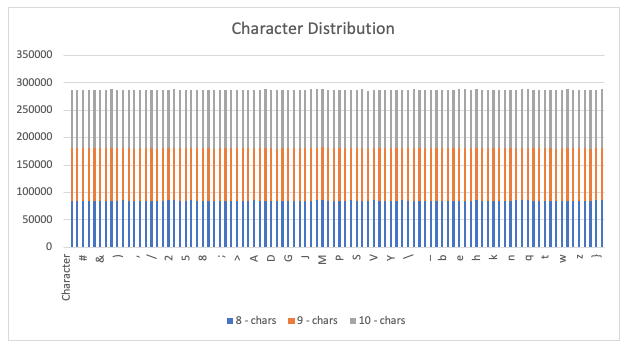
Logan was correct. The character distribution across all the passwords of all tested lengths is the same, which is great to see. An interesting side note…it appears that LastPass does not include the space character in its randomly generated passwords! This means our key space for characters to test can be reduced by one. Woo, efficiencies!
Regardless, we can use the fact that some character classes are more likely to appear in a randomly generated password over others to our advantage. We could build a recovery method that uses statistically likely character classes.
To build our attack we’re going to use hashcat’s mask attack. If you’re unfamiliar with hashcat masks, we can essentially instruct hashcat to test all possible characters of a given set by using the following table:
| Mask | Character Set |
| ?l | abcdefghijklmnopqrstuvwxyz |
| ?u | ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| ?d | 0123456789 |
| ?h | 0123456789abcdef |
| ?H | 0123456789ABCDEF |
| ?s | «space»!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ |
| ?a | ?l?u?d?s |
| ?b | 0x00 - 0xff |
For example, if we wanted to test all possible permutations of a password that was 4 characters in length and consisted of only lowercase letters, we’d use ?l?l?l?l.
We can even specify custom character sets. For example, if I only wanted to test lowercase letters and digits, I would use -1 ?l?d to define a new character class 1. Then I could specify ?1?1?1?1?1?1?1?1 to make a mask to test all possible combinations of lowercase letters and digits for 8-character passwords.
Using the character class distributions, we’ll create the masks below. We'll also swap out hashcat's standard ?s to denote all symbols and replace?s with our custom class to exclude the space character.
| Special Character Class | |
| -1 | !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ |
| 8 Characters | ||
| Character Class | Count | Mask |
| Lower Alpha | 2 | ?u?u |
| Upper Alpha | 2 | ?l?l |
| Digit | 1 [1] | ?d |
| Symbol | 3 | ?1?1?1 |
[1] Technically, in our graphing, we see that zero digits is more frequent than one digit, but for this test I'm going to force a minimum of one digit.
| 9 Characters [2] | ||
| Character Class | Count | Mask |
| Lower Alpha | 2 | ?l?l |
| Upper Alpha | 3 | ?u?u?u |
| Digit | 1 | ?d |
| Symbol | 3 | ?1?1?1 |
[2] We could have easily swapped the values for Lower Alpha and Upper Alpha because their frequencies were relatively the same for 9-character passwords.
| 10 Characters | ||
| Character Class | Count | Mask |
| Lower Alpha | 3 | ?l?l?l |
| Upper Alpha | 3 | ?u?u?u |
| Digit | 1 | ?d |
| Symbol | 3 | ?1?1?1 |
Focusing on 8-character passwords, our mask now looks something like: ?u?u?l?l?s?s?s?d. We should pay attention to the position of each character class to ensure that we test all possible combinations of these character class sets. Meaning, using the above character class sets, we need to build a list of masks like:
?u?u?l?l?s?s?s?d
?u?u?l?l?s?s?d?s
?u?u?l?l?s?d?s?s
?u?u?l?l?d?s?s?s
?u?u?l?d?l?s?s?s
…
So, how many permutations will we need? To find out, normally you would take the total number of positions and find their factorial to get the answer (8x7x6x5x4x3x2x1). Because we are only interested in the unique patterns, we would do:
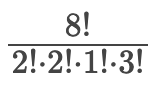
The numerator is the length of the password factorial, and the denominator is the number in each character class factorial. In our case, 1,080 different hashcat masks are required for our 8-character long password.

Thankfully, hashcat supports submitting a file of masks appropriately called an hcmask file. So, after generating a file of 1,680 masks, I tested my theory in several ways:
- Tested the 1,680 masks against the initial set of 1M randomly generated 8-character passwords
- Tested the 1,680 masks against a new set of 1M randomly generated 8-character passwords
- Tested the 1,680 masks against ALL uncracked NTLM hashes in TrustedSec’s list of unrecovered hashes
Then I repeated the above for the 9 and 10-character masks and recorded the rate of cracked hashes over a period of 1 hour, 2 hours, and 3 hours. For a baseline, I also measured the total number of hashes recovered while using the standard brute-force methods. All tests were performed using 2x GeForce RTX 2080 Ti’s. The results are as follows:
| 8 Characters 1 hour | ||
| Hashfiles | Standard Brute-Force | TrustedSec 1,680 hcmasks |
| Initial 1M 8-character Passwords | 28,825 (2.88%) | 29,314 (2.93%) |
| New set of 1M 8-character Passwords | 24,638 (2.46%) | 29,126 (2.91%) |
| All Uncracked NTLM Hashes | 30 (0.003%) | 0 (0.00%) |
| 8 Characters 2 hours | ||
| Hashfiles | Standard Brute-Force | TrustedSec 1,680 hcmasks |
| Initial 1M 8-character Passwords | 67,439 (6.74%) | 37,520 (3.75%) (77 Minutes) |
| New set of 1M 8-character Passwords | 68,299 (4.69%) | 37,391 (3.74%) (78 Minutes) |
| All Uncracked NTLM Hashes | 50 (0.005%) | 0 (0.00%) (72 Minutes) |
| 8 Characters 3 hours | ||
| Hashfiles | Standard Brute-Force | TrustedSec 1,680 hcmasks |
| Initial 1M 8-character Passwords | 106,529 (10.65%) | 37,520 (3.75%) (77 Minutes) |
| New set of 1M 8-character Passwords | 107,498 (10.75%) | 37,391 (3.74%) (78 Minutes) |
| All Uncracked NTLM Hashes | 62 (0.006%) | 0 (0.00%) (72 Minutes) |
| 9 Characters 1 hour | ||
| Hashfiles | Standard Brute-Force | TrustedSec 5,040 hcmasks |
| Initial 1M 9-character Passwords | 0 (0.00%) | 321 (0.03%) |
| New set of 1M 9-character Passwords | 0 (0.00%) | 310 (0.03%) |
| All Uncracked NTLM Hashes | 0 (0.00%) | 2 (0.00%) |
| 9 Characters 2 hours | ||
| Hashfiles | Standard Brute-Force | TrustedSec 5,040 hcmasks |
| Initial 1M 9-character Passwords | 0 (0.00%) | 630 (0.06%) |
| New set of 1M 9-character Passwords | 0 (0.00%) | 630 (0.06%) |
| All Uncracked NTLM Hashes | 0 (0.00%) | 2 (0.00%) |
| 9 Characters 3 hours | ||
| Hashfiles | Standard Brute-Force | TrustedSec 5,040 hcmasks |
| Initial 1M 9-character Passwords | 0 (0.00%) | 935 (0.09%) |
| New set of 1M 9-character Passwords | 0 (0.00%) | 936 (0.09%) |
| All Uncracked NTLM Hashes | 0 (0.00%) | 4 (0.00%) |
| 10 Characters 1 hour | ||
| Hashfiles | Standard Brute-Force | TrustedSec 16,800 hcmasks |
| Initial 1M 10-character Passwords | Overflow | 3 (0.00%) |
| New set of 1M 10-character Passwords | Overflow | 3 (0.00%) |
| All Uncracked NTLM Hashes | Overflow | 0 (0.00%) |
| 10 Characters 2 hours | ||
| Hashfiles | Standard Brute-Force | TrustedSec 16,800 hcmasks |
| Initial 1M 10-character Passwords | Overflow | 5 (0.00%) |
| New set of 1M 10-character Passwords | Overflow | 8 (0.00%) |
| All Uncracked NTLM Hashes | Overflow | 0 (0.00%) |
| 10 Characters 3 hours | ||
| Hashfiles | Standard Brute-Force | TrustedSec 16,800 hcmasks |
| Initial 1M 10-character Passwords | Overflow | 10 (0.01%) |
| New set of 1M 10-character Passwords | Overflow | 14 (0.01%) |
| All Uncracked NTLM Hashes | Overflow | 0 (0.00%) |
Conclusion
Did we find a better way to crack randomly generated passwords?

Looking at the tables above, we can see that using these masks does get us more results in a shorter period of time when used with randomly generated passwords, but their effectiveness is not sustainable This is because the brute-force approach covers the entire possible key space, whereas our masks only cover a subset. Put another way, these masks cover the more common random password character classes instead of attempting all possible character classes, and therefore using them can sometimes result in a quicker recovery of a randomly generated password.