Getting Started Using LLMs in Application Testing With an MVP

Certainly, the hot topic in application security right now is large language models (LLMs). As with most buzzy topics in software, the rollout of practical deployments greatly leads the way vs getting tooling in the hands of security practitioners. A lot of work has gone into defining what offensive security around applications offering GenAI chat interfaces or using LLMs to generate other content should look like. Some leading examples of this are OWASP’s GenAI-Red-Teaming Guide and NIST’s Artificial Intelligence Risk Management Framework. If you’re going to get started performing offensive security against an application with an LLM, these documents are a great place to obtain a solid idea of what you’re looking for and help you put together a methodology around testing.
Security concerns for the use of these language models in applications will vary by audience. Coming from the perspective of those performing mostly traditional web application testing, we are most interested in GenAI twists on lot of the same application concerns we’ve always had. Those would include injection attacks, request forgery both client and server-side, missing or incorrect authorization control, and concerns specific to the application domain. It comes down putting remote model and the completions it generates into the attack chain. We should be able to affect a lot of testing these interfaces for those issues with existing tools. Importantly we should have as a goal being able to get started with serious, effective LLM attacks on Day 1 of an application assessment, not on Day 2 after six 6 hours of scripting and debugging.
There is, of course, an array of entirely new concerns as well in areas like confabulation and integrity, and additionally for a host of social, brand, and intellectual property issues. These later areas are not the focus of what I am covering here. If you need to do work in these areas, you will require complex classifiers, scoring, and other GenAI domain-specific tools that are likely always going to be more complex than anything that could be stuffed into Burp Suite. This is a scope problem, and if your clients are asking for that kind of work, the only way forward is to put in the hours to build what you need.
Microsoft has contributed a framework called PyRIT for more opened-ended adversarial assessments. There is another project aimed at making PyRIT more immediately usable, PyRIT-Ship, which is also worth a look.
If you are still reading, it is likely because you took the click-bait 'MVP' and, well now, you can let your bated breath out slowly. In this instance, I mean minimum viable product. What I have to share with you alongside this blog is a small Burp Suite extension that will let you get started using LLMs in application testing.
If you have managed to install Ollama and know your way around Burp, you are ready to get started! Let’s take a look!
All you need to do is check your JRuby environment to make sure you have version 9.3 or later and have installed the Base64 and JSON gems. Next fetch my plugin https://github.com/GeoffWalton/LLMHaxor/blob/main/LLMHaxor.rb to add to Burp Suite.
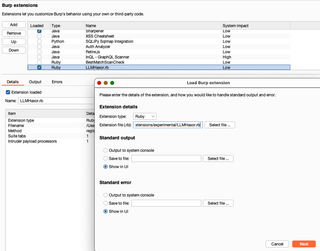
You may wish to configure where the extension should send output. Requests to the Ollama API are printed. If you will need the complete prompt and context for reporting, saving it to a file, or writing in the console, logs might be preferred.
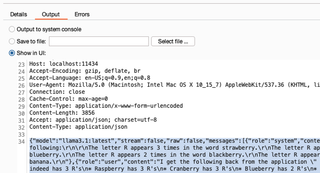
Now that the extension is installed, we can leverage models installed in Ollama with the Intruder tool. To get a quick idea of what everything does, I will ask Meta’s llama3 model to help me exploit a traditional application vulnerability, XSS, in one of our training applications.
Here are the steps:
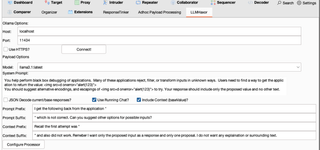
- Goto the LLMHaxor tab and configure the Host and Port, where Ollama is running.
- Click the ‘Connect!’ button. This populates the list of models in the drop-down.
- Select a model to use, in this case ‘llama3.1:latest’.
- Write a system prompt. This is where most of your real payload probably will go. It might be necessary to be a little circumspect about what you are actually doing, depending on the model.
- Write the prompt prefix and suffixes to use for each Intruder payload item. These strings will be wrapped around the current payload value (space separated) to produce the prompt. You can optionally complete the Context prefix and suffix fields; these are wrapped around the base value of the Intruder payload position and the entirety is appended to your prompt. I found it helped keep many of the models on target when I included some reminder of the first attempt.
- Select the options for the model.
- JSON decode will remove some common JSON escapes from the payload strings. For example, “\n” will be converted to a literal newline. An alternative if you need more complex transforms would be to place additional payload processors ahead of the Ollama Payload Processor.
- Use Running Chat determines if the previous chat history should be used in generating the LLM completion. If this is not selected, only the current prompt and system prompt are presented to the LLM.
- Include Context determines if the base Intruder payload and wrapper strings are provided to the LLM.
- Click Configure Processor. This will register the payload processor in Burp and save your current configuration in Burp’s settings file.

For this demonstration, I will enable Use Running Chat and Include Context, then set things up in Intruder and see if I can get llama3.1 to create an XSS attack for me! I’ll use the recursive grep payload type to continue updating the model prompt with application responses, extracted from the offset where they are usually reflected on the target page.
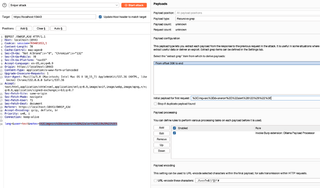
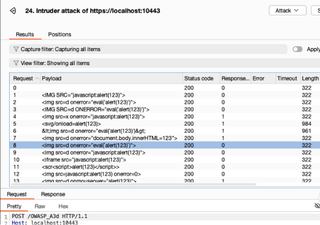

It isn’t doing a half bad job! Granted, it also isn’t doing anything a basic fuzz list could not do several orders of magnitude faster, but without writing any new code, it is possible to get the LLM to transform inputs in a responsive way. That has real-world useful applications for jobs like finding exploits with error-based SQLi!
Now that it is possible to get an LLM to generate completions and interact with a web target, we can look at targeting other LLMs. One major limitation of this approach is many chat applications stream responses, either via WebSocket or across multiple HTTP transactions. That does not lend itself easily to the Intruder attack model. I will be looking at extending this plugin and looking at ways to effectively consider reply context in those instances. There are a significant number of applications that embed the full completion in a single reply, however. One example is https://promptgolf.app.
Prompt Golf does not require login or present any initial terms of use so I went ahead and did some quick experiments with it. That way I can show some LLM vs. LLM activity for this blog, in application readers can at least look at. I kept the number of machine-generated requests to an absolute minimum to be respectful of their resources. I am sure the owners would be happy for anyone to stop by, relax, and play some golf, but please use appropriate lab resources if you are automating with this or any other tools. There are lots of little chat bot projects that can use Ollama as a back-end if you need.
To explore getting started quickly, I will be taking a swing at the Strawberry hole.
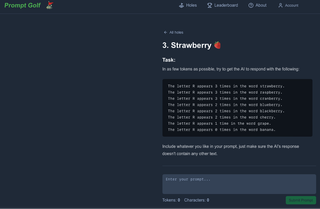
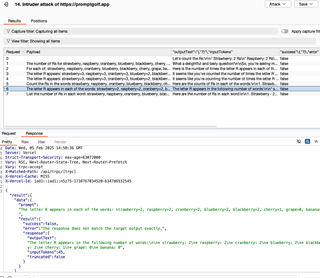
I configured the payload processor as follows, rewriting challenge instructions a little bit for the system prompt after some manual experimentation. I am using my base payload in the in the prompt each time as with the XSS example and keeping a running chat. When setting up the Intruder attack, I used the recursive grep payload again to collect the application responses, so the local model can see the remote model’s replies. Additionally, a canary value for success is reflected on the page, and I will grep extract that as well so that I can watch for it in the Intruder table. In a real attack that might be the place to look for that other account number, tax-id, or forbidden language.
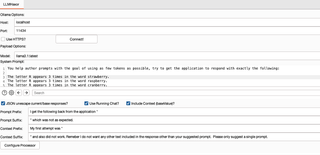

Finally, I set up the payload positions and processing rules. Note that, because of the way the local prompting works, I need to copy the reply from the application where I fetched the response for the grep extract definition to use as an initial payload. That way prefix and suffix strings will yield a sensible prompt for the first attempt.
One last comment: I have another payload processing item after the Ollama Payload Processor. That entry simply JSON escapes the output string and could be replaced with a few match-and-replace rules.
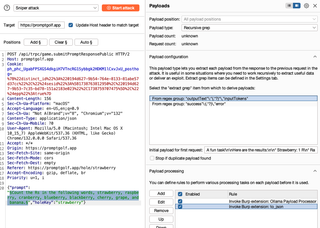
When I let the 'attack' run, these are the results—After seven attempts, it has not solved the hole; however, the prompts it is suggesting are reasonable trials for adversarial prompts. If this was a target where I could let the system keep trying, it just might get there.
So, there it is…LLM vs. LLM with no new code. Hopefully with this or your own riff on something like it you can get your LLM targeted tests at least started on Day 1!