From Chaos to Clarity: Organizing Data With Structured Formats

1.1 Introduction
About a year ago, we introduced a logging utility into our internal tooling on the Targeted Operations team to standardize how we output data (as a bonus, this also served us aesthetically with pretty logs). This project was then rapidly adopted across tooling and eventually catalyzed the idea for a centralized repository of engagement-relevant object definitions. We then introduced a shared set of data structures/models for various entities that we encounter daily, things like:
- Users
- Domains
- Applications
- Hosts
Since then, it has developed into a suite of tools encompassing a library for parsing public tools into objects, and a secondary project to ingest, display, and provide search functionality whilst also integrating the ELK Stack and infrastructure logging from C2 and Redirectors with our standardized objects.
With that said, the focus of the tooling has been to create and link disparate tool output together via the standardized object definitions. For example, the User data structure has become quite verbose encompassing data from AD, Azure, breaches, user workstation activity, and various other things.
With the rise of Nemesis from SpecterOps, it seems that others have identified that the chaos in our directories is not maintainable, and we are potentially missing out on vital pieces of information without our data, purely because the correlation between them is not there.
SpecterOps has made several posts on this topic, with these two (2) discussing this very problem:
In this blog post, I will explore a subset of the internal models and parsing done to solve this and attempt to persuade the industry to migrate away from traditional, unstructured log files and begin to develop and adopt a standardized data object model.
1.2 The Power of Structured Data
Rather than simply listing the benefits of working with structured data, I will instead present them through the lens of a common operational scenario.
1.2.1 OSINT/Users
During an OSINT portion of an engagement, it’s typical to aggregate relevant information from public services like DeHashed or hunter.io. If we cURL the hunter.io API, we can pull a list of email addresses and where they came from, confidence score, and various other metadata.
A list of email addresses is great, but augmenting the verbatim raw output from our sources through the introduction of related metadata can lead to some interesting and operationally significant scenarios. At this point, it is useful for building out a more curated list of phishing targets.
Now, if we incorporate DeHashed into this, we can get the following information:
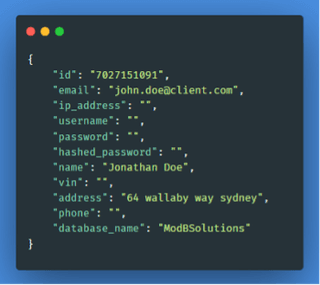
Now we are gaining more valuable information like phone numbers, locations, potential passwords, and so on.
A step further! Combine this with some output from LinkedIn, and now you are getting job titles and more potential social networking/contact information.
Attribute | Value | Source |
Username | John.doe | DeHashed |
DeHashed, hunter.io | ||
Location | US | DeHashed, LinkedIn |
Job Title | Salesperson |
Using this simple and ubiquitous example, we can build a common data structure from a series of sources. Having this User record defined allows us to not only extrapolate relationships in disparate data we may not have identified previously, but it also enables us to cleanly reference, augment, and work with the object across our operational phases. For OSINT, when we want to move to a phone-based phishing campaign, we can quickly reference all users with an email address associated with our target and where a phone number is available. Using downstream tooling that imports and understands the same User identity lets us seamlessly configure and launch the desired campaign.
1.2.2 External Assets/Bug Bounty
Enumerating external assets goes hand in hand with the bug bounty methodology. Often, we take a single point of entry, typically a domain name, and identify assets related to it. For a single domain object, you may identify subdomains, web applications, integrations such as Okta, and so on. Being able to take a domain and quickly see the bigger picture of it may create new leads to investigate.
For those continuous engagements or bug bounty hunters eagerly waiting for Tinder to create a new subdomain, this object-driven approach works well too. Say you are working on Tinder on HackerOne and want to keep an eye out for new infrastructure. Utilizing this model and enrichment strategy allows you to move away from 1708434014_subfinder_domain.com.txt style files and more into a database structure where existing subdomains are enriched, and new ones are added to the database. In this scenario, you may have a script that uses subfinder, HTTPX, and katana. As this tool is executed and parsed, new objects are created. If this object already exists but a new path or subdomain is identified, then that object is updated.
At this point you have clean objects being created and updated. The next step is to be able to quickly identify them. As this object transforms to JSON, they can be sent over to ElasticSearch for indexing and querying.
1.2.3 Hosts
Conversely, let’s discuss the Host models at the post-exploitation level. This can come from a variety of diverse sources like Nmap, NetExec, and general networking tools. Or they can originate from something with much more data like BloodHound. To make this even more complex, you could even generate an object from the host that you are on. Then, in a seatbelt-style enumeration, extract processes, services, local users, directories, and anything else to create an offline copy of this host. This is particularly useful on initial landing when you are performing initial reconnaissance of the host. Things of interest may be items such as services, processes registry values, and so on.
Once they have been collected, they can be abstracted from the environment to leave us with pure Windows Service level information, with no client data, and they could be tracked long-term across multiple engagements and compared/documented for future reference where another operator may be able to exploit it, then repopulating the object to track that.
Now, in addition to assisting in unifying downstream post exploitation and reporting toolkits, we can use data structures in real time to provide contextually relevant feedback to red team operators.
Overall, when you combine external-facing resources like Nmap and CrackMapExec with local information from being on the host, the objects could then include ports, local services, exposed services, running applications, registry values, local users and session, AD/Azure configurations, and so on. This provides full visibility into that asset and potentially leads to innovative ideas and motivations for the operator.
1.3 Structuring the Data
For this, Python dataclasses were used. In hindsight, protobuf may have been a better solution due to its interoperability across programming languages. Using dataclasses locks us into Python, which works internally, but if this were made public and adopted elsewhere, it is a limitation. That said, migrating from dataclasses to protobuf is quite straightforward and could support both for future public releases.
So, what are dataclasses? It is quite literally a Python class that allows us to store and manage data within Python. For more information on dataclasses, I highly recommend This Is Why Python Data Classes Are Awesome by ArjanCodes.
To define an object, we simply use the @dataclass decorator in a class and define the class members with the type and a default_factory of the member. This came in clutch when we looked at converting the objects to JSON for database storage. The default_factory will set the correct empty value. For example, str is “”, int is , and list is [] and so on. If these values are None, then our database of choice, MongoDB, will not be happy.
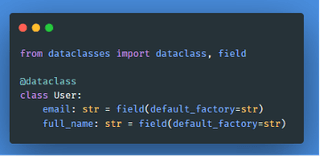
After the dataclass structure is defined, creating an instance of the object is simple.

Now, this is all in Python and is not usable elsewhere. To fix that, dataclasses-json is used to convert the object to a dictionary and this is why default_factory is so important. dataclasses-json will use these default types to figure out how to type the value. A more complete example of this can be seen below.
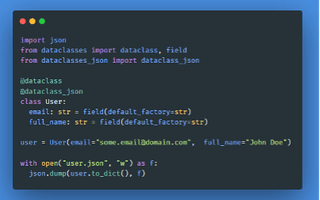
In the above example, we are setting up the User(data)class through the inclusion of the corresponding required decorators. After the User class is defined, we instantiate a new instance of our class, User. Finally, using to_dict(), we are able easily to dump all attributes of our User instance to a JSON file.
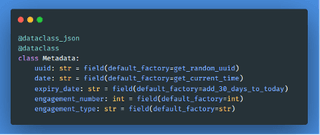
Across an engagement, tens of thousands of these could be created. To track where they came from, when they were obtained, etc., raw operational data is augmented with a corresponding Metadata class that is used to track all the information about the relevant object. This design choice was made so that we can accurately track the object, but also if we decide to go with long-term storage of that object, we can track which engagement it was. The uuid can be used to query for that specific object with KQL for ELK, or within our custom back end.
Now, let’s expand this to be more careful with the attributes by implementing smaller dataclasses to hold more information. In this example, an Email and Username class has been created, which allows us to be more granular with our information through the introduction of a verified value. This is useful when the origin of the data is something we cannot confirm. For example, if we obtain this by generating an email address based on a user's name (e.g., from a LinkedIn enumeration tool), then the verified bool will be false. However, if we pull it from something like TeamFiltration where we have actively verified the email address, then it is true. Further, we have added some more values such as full name, department, and title. Augmenting disparate tools and techniques builds a stronger data set.
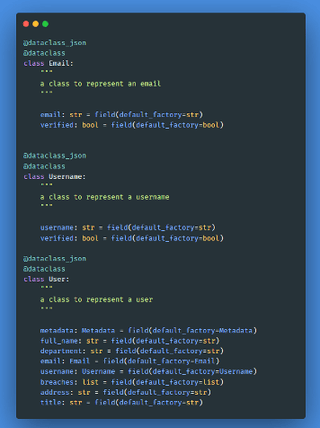
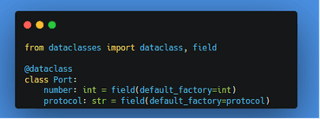
The Host model can become quite large, so I will only show a few examples of the data collected. Let’s start by defining the inner models. The simplest is the Port model, which, for now, only needs to consist of protocol and number.
If we repeat this process for things like Windows Services, Processes, Registry, Azure Devices, installed applications, network interfaces, and so on, we get a model that looks like this:
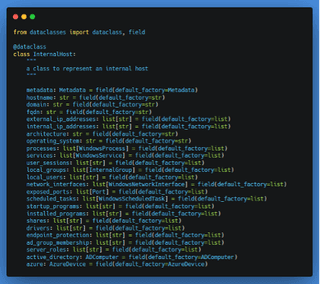
When initial access is achieved, our helper utilities can produce most of the host-specific information immediately and link it back to the C2 infrastructure. This provides a clear picture of communication to and from the host as well as access to the data offline. This also leads to potential for scrubbing the data and storing parts of it long term for cross-referencing for previous exploitation across the team.
1.4 Data Structures in Practice
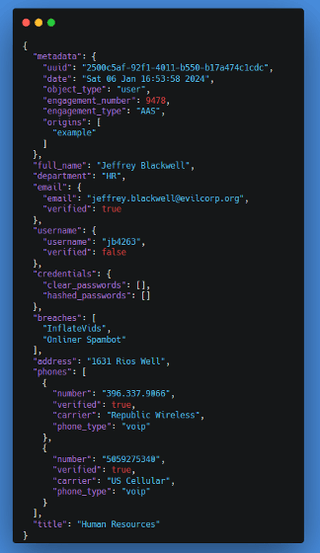
Let’s look at this in practice with three (3) objects with all fields populated with test data using a dev project utilizing Faker where possible. The User object is massive, so a partially filled out one is below, and a full one is accessible here.
To continue the narrative of OSINT, because it is the easiest to show examples of, we have a ton of data available to us from various sources. Using something like KQL and ELK, we can quickly extract information that could directly lead to a campaign or be inspiration for a campaign. In Kibana, a query such as the following can return a list of users for an SMS campaign.
email.verified : true and not email.email : "" and phones.verified : true and not phones.number : "" and not title : ""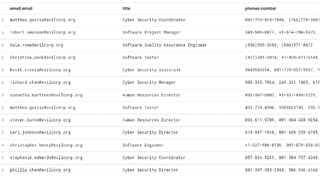
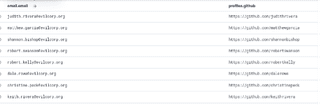
Ultimately, having this data available can provide new avenues of attack. The following is an example of users with GitHub profiles, which may lead to further enumeration within the repositories for exposed information relating to the target.
If we are searching for server information, then we can do things like:
server_roles :(Citrix or Jenkins)
Or:
operating_system : macOS and endpoint_protection : *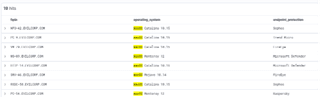
Reproducing this with data from disparate tools would be tiresome. We would need to manually parse, combine, and understand where all the data is. From this perspective, detailed data querying is beyond its capabilities. Using this model, standardized output and parsing enables operators to draw on the specific strengths of each tool and unveil new or hidden connections among the data you already have.
1.5 Conclusion
Querying the data is not the end-all-be-all structured data, but it is one of the benefits. As we ingest more data and build out and populate objects, we aim to give the operators new insight into the data that has already been collected and facilitate the identification of new attack paths and object relations.