dirDevil: Hiding Code and Content Within Folder Structures

Welcome back to another round of "Hiding in Plain Sight," exploring weird places to stash data or payloads. In our last edition, we explored an easy method of encoding a payload into RGB values of a PNG file and hosting it in public places. (imgDevil Github)
Today, we are going to experiment with a method for hiding data—a "fileless" storage solution, in a sense.
If you just wanna see how it all ends, you can skip to the TL;DR at the end of this post. If you're curious about how we might go about this, read on!
Fileless Data Storage
Anti-virus (AV) software examines files. Files can be malicious. Files are what store data. And so, AV software examines files. (Yes, AV can also monitor processes/behavior but stick with me here…)
Similarly, when Data Loss Prevention (DLP) software tries to detect the presence of PII or other sensitive data, it checks the contents of files. Files are where data is stored.
I get it—it's no surprise that software examines files. But what about folders? Not files that are in folders, but the folders themselves. The containers that are used to hold other containers or files. Does anything examine folders? What is there even to examine?
Would a bunch of empty folders with GUIDs as their name set off any AV or DLP solution?
If you were to scan these folders with an AV, would they even find anything to scan? 0 files. 220 folders.

What if an admin were to notice folders like this under C:\temp\ or within a user's AppData folder? Would they look twice? Or would they see it and guess it belongs to some back-end system or application something-or-other and ignore it?
While folders don't store data in the traditional sense of a file*, they quite readily store data in the form of folder names. After all, folder names are strings. And there's structure to this data. Folders exist in relation to each other hierarchically. You can have subfolders or parent (super) folders. These folder names and their relationships are stored someplace, even if they don't appear to take up space on disk.
* Alright, you might be screaming at your monitor at this point, "What about Alternate Data Streams!?" And you're right, you CAN store actual data in a folder's Alternate Data Stream (ADS) on Windows NTFS filesystems. Mac OS also has a version of the ADS. ADS allows for the storing of metadata in a filesystem-specific hidden resource for either a file or folder .You can store entire files inside the ADS even. However, these resources do not travel well. You cannot zip the folder or file containing the hidden resource and keep the ADS intact. In order to transfer a file with an ADS you must keep it in an NTFS formatted filesystem – virtual or real. Fwiw, WinRAR does* have a feature for preserving alternate data streams. And there's a bigger reason not to use them — ADS are known to be used by bad actors and can easily be searched for.
Planning
If you just want to see how the finished code works, skip ahead to ENCODING.
How will we hide our files within a directory structure?
The overall idea is to create a series of folders, one within another. These folders will contain chunks of our data. Then, we can list out the full path of sub-folders like this:
"folder1\folder2\folder3\folder4"
If we remove the folder delimiters, each folder name would be combined to form a string, recreating the data:
"folder1folder2folder3folder4"
By doing this, each folder name would be combined to form a string, recreating the data. Obviously, this is a simplified example.
We have a couple of considerations to keep in mind:
- Windows has a maximum path length of 260 characters.
- We don't want to mess with special characters in file names (quotes, ampersands, etc.)
Avoiding Special Characters
Since we want to store data that is not strictly alphanumeric, we need to encode our data. We can encode into anything that would be easy to store as a folder name. This means we want to avoid spaces or special characters in our encoding output.
Converting strings into hexadecimal is an easy way to avoid any special characters and maintain formatting or binary essentials such as non-printing characters. The downside is that a hexadecimal representation of ASCII takes up more space than the original ASCII itself, as it uses two characters to represent one character. The letter "A" in hexadecimal is described as "41," or more properly, "0x41."
One thing to consider is that pure hexadecimal might look suspicious as file names. For this reason, in this incarnation of this idea, I've decided to save the filenames in GUID format. GUIDs are especially common, thanks to Azure, and they may be seen as inscrutable, random names and ignored.
Length Limitations
We are limited to 260 characters in total for the path, by Windows. That includes what your current working directory is. As you can see, with a fairly normal-length username and working location, we are already at 39 characters.

This means that each of our directory paths must be well under this to avoid breaking.
Considering my choice to use GUID format, this reduces our space slightly further, with four dashes ("-") per GUID.
In most cases, we can get at least four to five GUID lengths in before we hit our limit.
Keeping the Data Ordered
So, if we have a bunch of folders, each with a string of data encapsulated within their structure, how do we keep them running in the correct order?
To solve this, I opted to use the first six characters of the GUID on any top-level folder as an index. While encoding, the script determines how many base-level folders will be needed and generates 6-character hexadecimal strings for each folder. It sorts these and stores them in an array.
Then, when each base-level folder is created, it has the associated line prefix called from the array, which is prepended to the folder name.
Our first line, "04dd72," would become:
04dd721a-3018-0603-5504-0a1311434f4d
------------------------------------
prefix| code --------------->If we iterate through our array list, prepending our generated prefixes to our encoded string on the base-level folders, we will create a hidden index.

This naming ensures that, when sorted by PowerShell in our decoder, it will come out in the right order. The 6-character length should minimize the chances of a collision in generating an index string, while still allowing for a large number of base folders if needed. The prefix length is easily changed if so desired. Also remember, this prepending will only be performed on the top-level folder, not every subfolder.
Encoding
For a proof of concept, we will use a small block of text that we all should be familiar with:

While we're using a text string to test, it's easy to change the input source to a file. PowerShell reads from a file easily with Get-Content.
We first take our input, whatever it is, and convert it into a byte stream. In this case, we can convert the string with the following:
$data_bytes = [System.Text.Encoding]::UTF8.GetBytes($example_data) This byte stream is then converted into hexadecimal.
$hexString = ($data_bytes | ForEach-Object { $_.ToString("X2") }) -join '' The result looks like this:

We have our data as a string of hexadecimal characters. Now, we want to figure out how many folders we'll need in order to contain our data.
Here's our math:
- 32 character GUIDs * 5 = 160 characters
- However, the first six of our characters are our index, so we are down to 154 characters per folder "structure" (the entire folder path)
$chunksize = 154 #our code chunk size
# take the hex string length, divide by our max length of 154 chars, and
# since we will likely get a float - e.g., 35.2, we add +1 and cast as int
$number_of_folders = [int]($hexString.Length / $chunksize) + 1
echo "We will generate $number_of_folders top-level folders."This brings us to a point about padding. We need to make sure that for the last top-level folder we create, the data will not fill out the entire string of GUIDs.
Imagine this is a GUID at the end of our code:
D3ADB33F-xxxx-xxxx-xxxx-xxxxxxxxxxxx
If only the first eight characters of the last line (folder) are filled, we need to pad out the rest of the character spaces with a GUID-friendly character set. Luckily, we have an easy solution: Pad it with 00 (0x00). This should not cause a problem in most cases.

Each GUID can hold 32 characters of data and takes up 36 characters total, including the dashes. Since we are using five of the 32-character GUIDS, for a total of 160 characters of data, 20 characters of dashes, and four slashes, this puts us at 184 characters, which means we have 76 characters of buffer for whatever filepath it is located at (e.g., C:\Users\trustedsec\) before we hit the Windows limit of 260 characters. If your base path is long you may find that you need to reduce this encoding to four of the 32-character GUIDS, and that's fine. It just means that there will be more base-level folders. No biggie, really.
Here's the tricky part: We convert our hexadecimal string into a series of paths consisting of folders with GUIDs as their names and create those paths.
# Split the string into chunks
$chunks = [regex]::Matches($paddedString, ".{1,$chunkSize}") | ForEach-Object { $_.Value }
$i = 0
# Process each chunk
foreach ($chunk in $chunks) {
$prefix = $hexArray[$i]
# Prepend the prefix
$chunkWithPrefix = $prefix + $chunk
# Split the chunk into 32-char segments and format as GUIDs
$guids = [regex]::Matches($chunkWithPrefix, ".{1,32}") | ForEach-Object {
$segment = $_.Value
$formattedGuid = ($segment -replace '(.{8})(.{4})(.{4})(.{4})(.{12})', '$1-$2-$3-$4-$5')
[guid]$formattedGuid
}
# array to hold our folders before we create them
$tmp_path_array = @()
# Process our GUIDs
$guids | ForEach-Object {
#Write-Output $_
$tmp_path_array+="$_"
}
#echo "Making directories:"
$fifthline = "{0}\{1}\{2}\{3}\{4}" -f $tmp_path_array[0], $tmp_path_array[1], $tmp_path_array[2], $tmp_path_array[3], $tmp_path_array[4]
echo $fifthline
#this -p option creates any required parent folders
mkdir -p "$fifthline" | out-null
$i++
} Here, we can see the output of the encoding. This is our file, encoded into folder paths. Each line represents a hierarchy of folders which contain part of our overall encoded string.

We have 44 different folders at the top level (base level). The first six characters of each line are a randomized 6-character hexadecimal, which was sorted alphabetically and prepended to each line. This allows us to sort by name and have each line come in order as it should, while appearing random.
The image below highlights the index section of each path line.
Here's what the generated top-level folders look like.
Here's an example of a folder tree structure:
Our base folder takes up zero bytes on the disk. Note the 220 folders.
DECODING
Using our special decoder ring, we can turn these folders back into a file.

To decode, we look at the top-level folders in our target directory. Then, in sorted order, we dive into each top-level folder, retrieving the entire path of the folder structure. Punctuation is stripped, and the hexadecimal is appended to a "hex stream" string variable.
Once all the top-level folder paths have been read in, the hex stream is converted to bytes and can either be displayed to screen or written to a file. Here is the full code of the decoder:
$rootDirectory = $currentDirectory
$rootDirectoryLevels = $rootDirectory.Path.split('\').Count
$decoder_hex_string = ""
$topLevelFolders = Get-ChildItem -Path $rootDirectory -Directory
# Iterate through each top-level folder
foreach ($folder in $topLevelFolders) {
# Get all subfolders recursively
$subFolders = Get-ChildItem -Path $folder.FullName -Directory -Recurse
# Find the deepest subfolder
$deepestSubFolder = $subFolders | Sort-Object { $_.FullName.Split('\').Count } -Descending | Select-Object -First 1
# Get the full path of the deepest subfolder
$trunc_path_split = $deepestSubFolder.Fullname.Split("\")
#this ensures we only pull in the path starting at our current location
$truncated_output = ($trunc_path_split[$rootDirectoryLevels..($trunc_path_split.Length - 1)] -join '\')
# now format it for our data to append to decoder_hex_string array
$purehex = $truncated_output.Substring(6).replace("-","").replace("\","")
$decoder_hex_string += $purehex
}
# Split the hex string into chunks of 2 characters (each representing a byte)
$decoded_bytes = [regex]::Matches($decoder_hex_string, '..') | ForEach-Object { [Convert]::ToByte($_.Value, 16) }
$outputpath = "$currentDirectory\decoded_output.file"
echo "Writing our payload to file: $outputpath"
# Write the byte stream to the file
Set-Content -Path $outputpath -Value $decoded_bytes -Encoding ByteIf we wanted to really make it concise, here is a minimalist version:
$a = Get-Location
$b = ""
foreach ($f in (gci -Path $a -ad)) {
$c = (gci -Path $f.FullName -ad -r | sort { $_.FullName.Split('\').Count } -d)[0]
$d = ($c.Fullname.Split("\")[$a.Path.split('\').Count..($c.Fullname.Split("\").Length - 1)] -join '\')
$b += $d.Substring(6).replace("-","").replace("\","")
}
$e = [regex]::Matches($b, '..') | % { [Convert]::ToByte($_.Value, 16) }
$g = "$($a.Path)\decoded_output.txt"
sc -Path $g -Value $e -Encoding Byte 
And, there it is! We can see that the file came out perfectly:

This process works for both text files and binaries. Beware of the file sizes, though!
The encoded folder structure won't technically count for disk space, as it's built into the file system. However, it is real data, and it does consume space (folder names are stored in the MFT on Windows or in the Catalog in MacOS). If you want to transfer it in a ZIP, it will take up more space than the original, as it needs to store all of that name data in an encoded form.
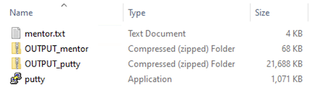
The screenshot above shows the compressed file sizes for both The Mentor text file and the Putty binary, compared to the original sizes. The compressed files above were made using the built-in ZIP in Windows.
It's unfortunate that ZIP, which is used by the built-in compression on Windows and MacOS, performs so poorly for this particular scenario. If you have access to other compression format unpackers, most would be preferable to ZIP.
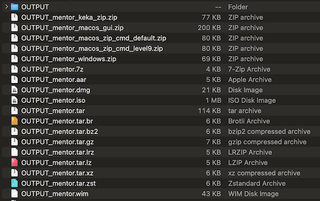
Unless otherwise specified in the filename, all compression was done with Keka on MacOS.
Conclusion - Pros and Cons
This was a fun exercise, but where could this be used? Also, what downsides are there to this?
Potential Uses:
- Hiding payloads or data on a system
- No apparent malicious code or sensitive data—just some weird GUID folders
- Hard to locate
- Can't search for files of any size
- Won't appear to take up disk space
- No static strings to key off of
- GUID format is changeable
- Evading AV static detections
- You still need to load the code, and that's the toughest part. But it's one less opportunity for detection via static strings.
- This might be all you need on a server. Workstations tend to have better EDR/AV systems. If you port this over to Linux, your chances of success go up greatly.
Downsides:
- Large file size when using zip format
- Putty went from 1,071KB to 21,688KB once zipped in the file folder structure.
- As noted, other compression methods fare much better.
- Won't evade good AV/EDR (still need to execute the code)
- This might involve an Invoke-Expression or other telltale command execution method that AV/EDR looks for.
- While you could load decoded PowerShell scripts or C# assembly from memory, to execute a normal binary, you will need to write it to disk.
- Bulky decoder/encoder script needed
- While the code can be minimized, it is not as concise as I had hoped.

In the end, this turned out to be more of a fun exercise than anything. While it's a neat trick to hide data on a system, I do not see this being terribly useful in the real world. The real takeaway is this: hiding data is limited only by your imagination.
A proof of concept can be found at https://github.com/nyxgeek/dirdevil
TL;DR: You can hide data in directory structures, and it will be more or less invisible without knowing how to decode it. It won't even show up as taking up space on disk. However, its real-world applications may be limited because it is the code execution itself which is often the difficulty with AV/EDR evasion.