- Blog
- Coverage-Driven Sustained Testing (CDST): A Graph-Oriented Model for Open-Ended Agentic Workflows
Coverage-Driven Sustained Testing (CDST): A Graph-Oriented Model for Open-Ended Agentic Workflows

Table of contents
1.1 Introduction
Ralph is a solid tool that makes agents do…more. It's defined as: an autonomous AI agent loop that runs repeatedly until all PRD items are complete. The purpose is for it to handle bigger plans and ensure context and positioning of the development is maintained. It's an improvement over the plan mode in tools like Claude Code and Cursor, as it expands the scope quite extensively.
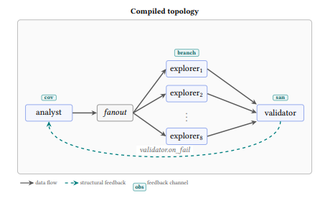
On that note, anybody using agents to do anything will typically follow the plan and execute model discussed in Plan-Then-Execute: An Empirical Study of User Trust and Team Performance When Using LLM Agents As A Daily Assistant. This works, and it's what makes these agentic tools work well. You ramble at it, it formulates a plan, and it builds it out. With these agentic tools, we also get a judge-ish component with the allow/disallow lists as mentioned in No Autonomy Without Scalable Oversight. However, where this gets tricky is when you want to distill the ability to be curious, dig deep, or generally get creative and keep going. This is where Coverage-Driven Sustained Testing (CDST) comes in.
Ultimately, CDST is a self-expanding agent loop that is driven by a structured state graph where the “next step” is always derived from an unexplored, or under-explored, area. In this case, it’s a graph-driven exploration engine that is reminiscent of Novelty Search. While preparing for this blog, I found Synthesizing Multi-Agent Harnesses for Vulnerability Discovery, which discusses a similar node-based approach focusing on vulnerability hunting.
1.2 Concept
CDST is a mechanism to continuously give agents new ideas and new goals to pursue rather than fulfilling the plan and wrapping up. In this blog, I want to detail the implementation and ideas behind the concept. The bottom line comes down to: just don’t let agents determine what “done” means. More formally, “done” is not a semantic property of the agent but a property of the explored state space. CDST shifts termination logic away from the agent and into the system’s coverage model, allowing for open-ended work to be carried out.
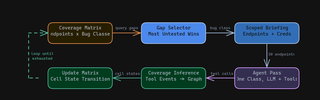
The loop queries the matrix for untested areas, picks whichever node has the most gaps, and builds a scoped briefing. For example, here are 30 endpoints, here are the credentials found so far, go test these for XSS.
From there, the agent does whatever the harness needs it to. The simplest pattern is to enter the planning loop with a fresh context with data pulled from the matrix to seed it. If strongly typed data models are available before hitting the agentic component, that's additional context on top of what CDST provides. Another example is reverse engineering: extract every function from a binary and those become nodes in the matrix. Whether it's 10 functions or 10,000, the loop will work through them. Each function gets analyzed for whatever the desired outcome is. The matrix tracks what's been looked at and what hasn't, which becomes another starting point later on where untested or bad results can become starting points or places to avoid on another pass. This is fundamentally different from task-list loops like Ralph, where it works through a predefined list of stories in a PRD; each one passes or it doesn't, and the loop picks the next incomplete one, spawns a fresh agent, and moves on.
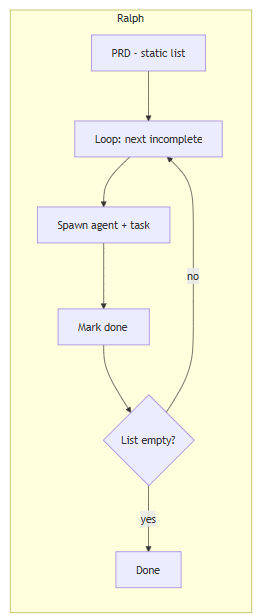
The work is known upfront and the loop is just execution. CDST doesn't have a predefined task list and the matrix generates the work. Gaps emerge from what hasn't been tested yet, credentials unlock new surface mid-run, and the loop keeps finding things to do that nobody wrote down. Ralph finishes when the list is empty. CDST finishes when the coverage says there's nothing left to test.
Traditional systems converge toward completion. CDST systems expand until coverage saturates. One final note is that this concept is targeting projects that have no definitive end. So, using CDST for code would not be effective due to coding projects having that definitive end goal.
A useful way to frame this is:
- Task-based systems reduce entropy by consuming a known backlog .
- CDST systems increase entropy locally (via discovery) while reducing global unknowns (via coverage).
Coverage is not always binary. In some domains, coverage is clear and measurable, and in others it is heuristic. There, saturation simply means new exploration is producing little additional value, rather than everything being fully known. At that point, the system can shift effort elsewhere, deepen promising paths, or stop on economic grounds rather than theoretical completeness. Below is a diagram that shows how this flow could work to go from coverage to deep-dive and back again.
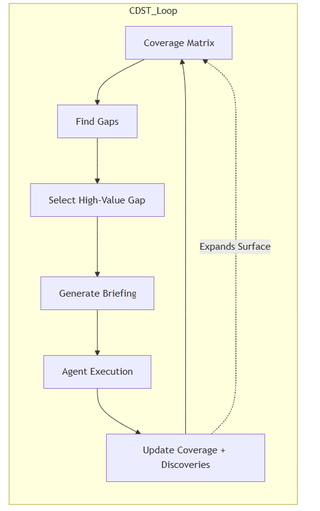
The real shift is that work is no longer predefined. For penetration testing or hacking in general, findings don’t terminate execution, but they create new nodes to start the process again. Those nodes become first-class targets and act as starting nodes while the system generates its own backlog dynamically. The following diagram shows the initial scope going through the process.
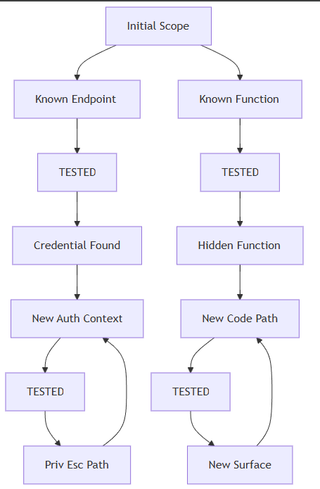
The matrix can be broken down into three (3) distinct phases:
- State Storage
- Discovery
- Prioritization
Importantly, “tested” is never a single boolean. Coverage is tracked against specific dimensions such as vulnerability class, technique used, authentication state, input path, or confidence level. A known endpoint may be tested for XSS but not SSRF, tested anonymously but not with credentials, or tested lightly but not deeply. The matrix, therefore, stores partial coverage states, not simple pass/fail labels.
1.3 Examples
The difference matters at scale because a traditional task list has a fixed size and the agent burns through it and stops. CDST's backlog is generated from the matrix. Every finding is a potential expansion, such as credentials unlock an authenticated surface or new endpoints enter the matrix mid-run. The loop has more to do after a successful exploit than before it. This is one of the key inversion points: successful work increases the future workload rather than reducing it.
There are two immediate stopping points:
- Time ceiling: after X minutes, quit
- Intervention: judge agent or human manual stop
1.3.1 Penetration Testing
To ground this, consider a simple vulnerability-driven view like the below. There are three (3) top-level bug classes: SSRF, XXE, and SQLi. They all go through a testing loop; XXE and SQLi don’t find anything, but SSRF does. This then branches off into further loops.
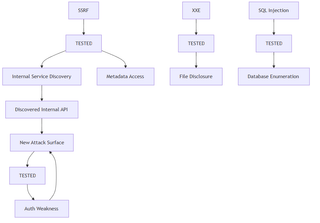
Now, using this loop, the agents agenda can grow with the scope. SSRF works, and the agents can hit internal services. An internal service is found, and cycle continues.
This creates what can be thought of as a branching discovery tree, where each positive signal increases the branching factor of the system dynamically.
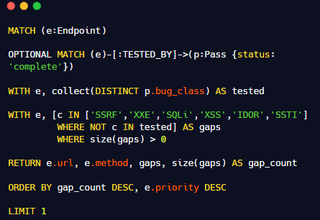
An example Neo4j query could look like this:
1.3.2 Reverse Engineering
CDST becomes much more obvious in reverse engineering. Assume this diagram:
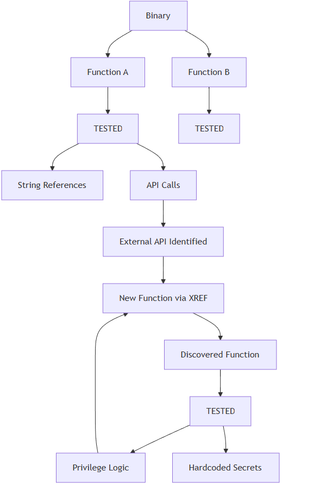
There is no predefined list of “all functions worth analyzing.”
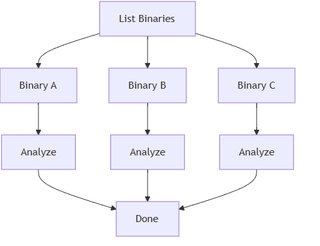
In some cases this might be preferable, but assume a deep analysis is required. Functions emerge via cross-references, data flow, and structure. The loop scales naturally whether there are 10 functions or 10,000 functions, it’s the same mechanism. In this setting, CDST effectively turns reverse engineering into a progressive graph traversal problem, where edges are not static calls but inferred relationships discovered during execution. In a mock Neo4j implementation, radare2 and lief are using to extract the Call Flow Graph (CFG) before utilizing the tree to generate points of interest based on categorized imports (Categorising DLL Exports with an LLM).
f.name | f.addr | f.role | f.cluster | focus_score | ||||
fcn.140004d00 | 0x140004d00 | data_movement | 17 | |||||
fcn.140004150 | 0x140004150 | data_movement | 14 | |||||
fcn.140002790 | 0x140002790 | crypto_like | 13 | |||||
fcn.140006660 | 0x140006660 | data_movement | 11 | |||||
fcn.1400035c0 | 0x1400035c0 | data_movement | 8 | |||||
fcn.140006760 | 0x140006760 | crypto_like | 7 | |||||
fcn.140002fe0 | 0x140002fe0 | data_movement | 7 | |||||
fcn.140002a60 | 0x140002a60 | data_movement | 6 | 7 | ||||
fcn.140001190 | 0x140001190 | crypto_like | 7 | |||||
fcn.140002c20 | 0x140002c20 | generic | 6 | |||||
fcn.140003bd0 | 0x140003bd0 | generic | 6 | |||||
fcn.140006a00 | 0x140006a00 | generic | 6 | |||||
fcn.140002b10 | 0x140002b10 | generic | 6 | |||||
fcn.140002680 | 0x140002680 | data_movement | 5 | 6 | ||||
fcn.140003420 | 0x140003420 | data_movement | 1 | 6 | ||||
fcn.140002630 | 0x140002630 | data_movement | 4 | 6 | ||||
fcn.140003510 | 0x140003510 | data_movement | 6 | |||||
fcn.1400067d0 | 0x1400067d0 | data_movement | 6 | |||||
fcn.1400027f0 | 0x1400027f0 | generic | 5 | |||||
fcn.1400073e0 | 0x1400073e0 | data_movement | 4 | 5 | ||||
fcn.140002920 | 0x140002920 | data_movement | 5 | |||||
fcn.140001890 | 0x140001890 | data_movement | 5 | |||||
fcn.140007910 | 0x140007910 | data_movement | 1 | 5 | ||||
fcn.140001ab0 | 0x140001ab0 | generic | 4 | |||||
fcn.1400025f0 | 0x1400025f0 | generic | 2 | 4 | ||||
These can then serve as a starting point for agents. Next, CDST can be used to determine how things flow together and allow agents to have a backlog of tasks. From each of these, new CDST entries can be made, increasing the scope and execution time.
1.4 Who Owns the Loop?
Once CDST is framed as a separate orchestration layer, a question follows immediately: who owns the loop?
There are two (2) model schools of thought: consultation and inversion.
1.4.1 Consultation Model
In the consultation model, the agent runtime owns the loop and it calls into CDST to ask what to work on next, gets a briefing back, runs a pass, and reports the results. CDST is an advisor. In practice, this can underperform because it relies on the agent deciding when to ask for external state. Many planner-style systems tend to stay within their immediate context unless strongly prompted otherwise, meaning useful matrix data may be ignored or consulted too late. As a result, performance is often better when relevant CDST context is injected upfront rather than left as an optional pull model.
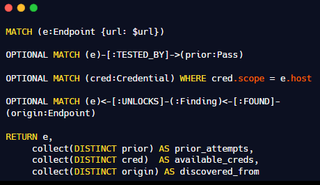
In the following diagram, we can see an example Cypher query for retrieving URLs by matching on:
- Does it have credentials?
- Has it been looked at before?
- Where was it found?
Again, these are placement concepts—this can be expanded as much as needed.
1.4.2 Inversion Model
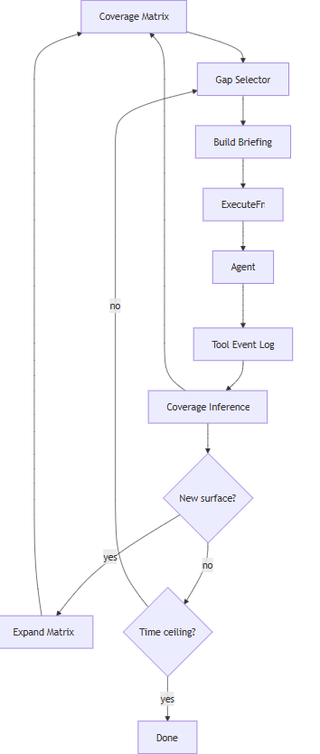
In the inversion model, CDST owns the loop and agents are workers. CDST decides what needs doing, assembles a scoped briefing from matrix state, hands it to whatever agent is registered, gets the tool event log back, infers coverage, and picks the next target. The agent doesn't know it's in a coverage loop; it just got a job.
The plug point is an ExecuteFn, which is a callable that accepts a briefing and returns a tool event log. What's behind it doesn't matter to CDST: it could be a full agent stack, a raw API call, or a human analyst.
1.5 The Architecture
My preferred model is the inversion model. Here, CDST has three (3) jobs:
- Populate the matrix
- Run the loop
- Expose the interface
The likely reason is incentive alignment. The model is rewarded for continuing the current reasoning chain, not for interrupting itself to fetch missing context. Pulling external state adds friction and expands the decision space. This requires the model to recognize what it does not yet know. Unless retrieval is strongly scaffolded, most agents default to acting on what is already in context rather than proactively seeking better inputs.
Step one is the matrix population, where anything can be a starting point. For a penetration testing engagement, this is a reconnaissance phase: endpoint discovery, parameter extraction, and technology detection. If this was a web application assessment, then API endpoints could be starting points. For an internal penetration test, it would be computers, and so on. For reverse engineering, it could be functions, import references, string references, etc.; there are a ton of possibilities to keep agents working here.
The core of it is the main loop. This is where gaps are queried, briefings are built, and surface expansion is addressed with three (3) layers of decision-making nested inside.
Internally, OODA (observe, orient, decide, act) governs each tool call within a pass. Gibbs' reflection is injected into the next briefing, asking what prior passes attempted, why techniques failed, and what to try differently. CDST governs the outer loop: which target, which mode, and when to transition from breadth sweep to depth retry.
The interface is an ExecuteFn. For an embedded agent stack, this is a direct function call. For external agents, it's an MCP server. CDST exposes a small set of tools and any MCP-capable agent can register as a worker without knowing anything about coverage loops.
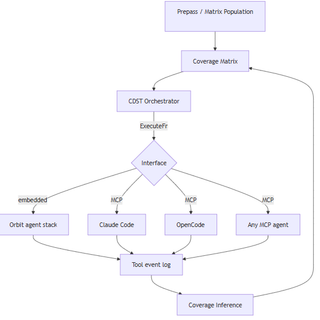
The inversion model gives these agentic frameworks the ability to utilize CDST, which could be done via MCP. Some example commands could be get_briefing, submit_result, report_finding, etc.
The agent registers as a worker, CDST hands briefings, the agent executes, and tool event logs come back. The agent never needs to know what a coverage matrix is. At this point, CDST can be thought of as a control plane.
1.6 Viability
Currently, agents do not maintain persistent memory in the same way external state systems do; they primarily operate within context windows. As sessions grow, earlier details can be compressed or lost. Summarization helps extend runtime but often trades detail for brevity. Plan-then-execute loops can reduce this pressure because they are typically shorter-lived, while CDST places more emphasis on solving it directly, since the loop may run continuously.
The matrix provides one (1) practical approach. Each pass begins with a fresh context seeded from a Neo4j query rather than relying on what the previous agent instance retained. Prior passes, credentials, findings, failed techniques, and newly discovered surface become the structured state in the graph and can be reintroduced when relevant. The agent handles short-horizon reasoning while the matrix stores longer-horizon state. This separation can make larger workloads more manageable by analyzing 10,000-function binaries or running multi-day assessments.
It is also worth noting that model memory is an active research area. Emerging architectures, including recurrent or memory-augmented transformer designs, may change how much external state management is needed over time.
This creates a strict separation of concerns:
- Short-term reasoning: agent
- Long-term memory: graph
- Orchestration: CDST loop
1.7 Conclusion
CDST reframes agent work as a coverage or search space problem over a dynamically expanding state graph, where execution is continuously re-seeded from discovered structure rather than pre-defined tasks. Instead of agents completing work, they continuously expand the space of what work "exists”. Granted, this has finite uses and isn’t viable for code, but it works well for open-ended objectives.