A 5-Minute Guide to HTTP Response Codes

If you've done any network scanning or application testing, you've run into your fair share of HTTP response codes. If not, these codes will show up in most network tools and vulnerability scanners, everything from curl, shodan.io, or Nessus to proxy tools like Burp Suite and ZAP.


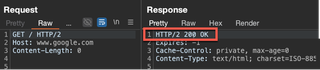
Response codes are an essential part of how HTTP works and indicates to the client whether the request sent was successful. If the request was all good, then you will most likely get a 200 OK response code.
The part that can get a little confusing is when the request is not a success. Response codes help the client know what went wrong, but sometimes these codes have misleading descriptions like a 302 Found.

So, you found the page I requested? Then why don’t I see the page content?
Requests can also return obscure codes you've likely never seen before, like 418 I'm a Teapot.

Here’s a short list of the most common codes and what they actually mean. If you encounter a code not on this list, there are plenty of resources (including the one at the bottom of this blog) that can help you figure out what the code means.
Some of the more common codes can be broken up into a few different sections. Successful requests range from 200-299, requests that redirect the user from 300-399, and errors from 400-599. There are also codes in the 100 range, but they are less common, so we will skip those here.
It’s important to note that not all response codes are errors. Typically, only response codes between 400-599 are indications that something went wrong, and the request needs to be modified to succeed.
We already covered what happens when our request is successful (200 OK), so let’s start with redirection codes. If you request an application URL but the requested page has moved or the server has a rule to redirect users, you will receive 301 Moved Permanently or 302 Found. These responses usually have a Location response header as well, to redirect the user to a new valid location.

You will commonly see these codes when you make URL requests with HTTP instead of HTTPS or when you exclude a subdomain in the request URL, like making a request to google.com instead of www.google.com. Servers can also have their own rules. For instance, if you navigate to example.com/me, the server may return a 302 Found and redirect the user to example.com/profile. Redirects are also used for error handling—a request to an unknown page may redirect the user to a /error page.
If you’re using a browser, you likely wouldn’t even notice this because the server will redirect you automatically by using the Location response header.
The next most common codes you will see are 400 codes, such as 401 Unauthorized.

Which means the page you are trying to return likely exists, but you don’t have an authorization header or cookie in your request that allows access to that resource.
You may also receive 403 Forbidden, which means you are likely logged in to the resource or authenticated to the service, and the page you are trying to access does exist, but your user doesn’t have access to that page.

403 also shows up a lot if you are making requests to an application that has a WAF implemented. Some WAFs will have a response header indicating that the 403 is being returned by the firewall and not the back-end server. This usually happens if your request contains known payloads used to probe for vulnerabilities, such as “or 1=1” or “alert(1)”.


If you are running a vulnerability scanner or a scanner that does forced browsing like gobuster or Wfuzz, you will most likely see a lot of 404 Not Found, which means the page you are requesting doesn’t exist and there are no rules in place to redirect the user to another URL.

Automated scanners also tend to return 429 Too Many Requests, which is usually because the user is making too many requests to the server from the same IP address in a short amount of time.

Lastly, if you are making requests to older applications or applications in development, you may encounter some 500 Internal Error codes. A 500 code simply means that something in the request caused an error on the server.

The software running on the server doesn’t have error handling for that specific error, so the server returns the 500 code. This is a common identifier used in SQLi attacks because it can indicate a malformed SQL query.
In certain frameworks, the stack trace of the error may also be presented to the user in the response body. These errors can provide internal file paths and database details and should only be allowed in restricted development environments.

There are plenty of other response codes, but the most common HTTP methods that are used are GET and POST, and they will more often than not return one of the codes above.

If other methods are used like PATCH and PUT or files are being uploaded, then you can see a host of other codes to let you know what’s going on.
Hopefully, next time your scanner returns a 401 or a 403, you’ll be able to understand the difference —especially if you are trying to run a credentialed scan that should be returning a 200 OK. In the end, as long as you know your response is not a teapot, you’ll be able to figure out what’s going on.

Source: